The first ever conference on Probabilstic Programming (PROBPROG 2018) was recently held at MIT. If you don’t know it, probabilistic programming is an exciting new field, that augments traditional programming languages with constructs from probability theory, including random variables, distributions and conditioning. I genuinly believe that probabilistic programming is going to change the way we think about programming, in the same way that deep learning revolution did around five years ago.

Probabilistic Programming
“The fundamental cause of the trouble is that in the modern world the stupid are cocksure while the intelligent are full of doubt.”
– Bertand Russell
Probabilistic programming is a machine learning technique, in that it allows inference of model parameters given data. It is based on the rigorous framework of Bayesian reasoning, which also has a nice intuitive interpretation that closely matches the way we usually think about learning and science in general. Compared to traditional machine learning techniques, there are three key advantages:
- It is possible to explicitly use domain knowledge by providing prior distributions over model parameters.
- The result of inference is a full Bayesian posterior probability distribution, allowing richer calculations of moments (e.g., mean, variance) and measures (e.g., median, skewness, kurtosis), and quantify uncertainty about particular outcomes.
- Most parameters are usually fixed or directly related to data, which makes models interpretable.
If you come from a Bayesian data analysis world, you would think that what I am claiming is not new, and you would be entirely correct. However, for a long time, one had to approximate complex (possibly intractable) integrals and large combinatorial sums by hand, which is a time consuming and error prone process. The revolution that I believe probabilistic programming provides is (semi-)automated techniques for deriving good approximation algorithms for Bayesian models, based on modern technologies like automated differentiation and deep neural networks. This should make the technique available to a wider audience, and allow experts to focus their time on solving domain problems rather than performing laborious automatable work.
Enough introduction for now, let us discuss some of the exciting news at the conference!
Exciting talks
Most talks this year were really good! To keep it short, I have however chosen the five talks I found most exciting to present in this post. I believe that all talks are recorded and may become available online at some point. I hope that you will take the opportunity to watch some of them when possible.
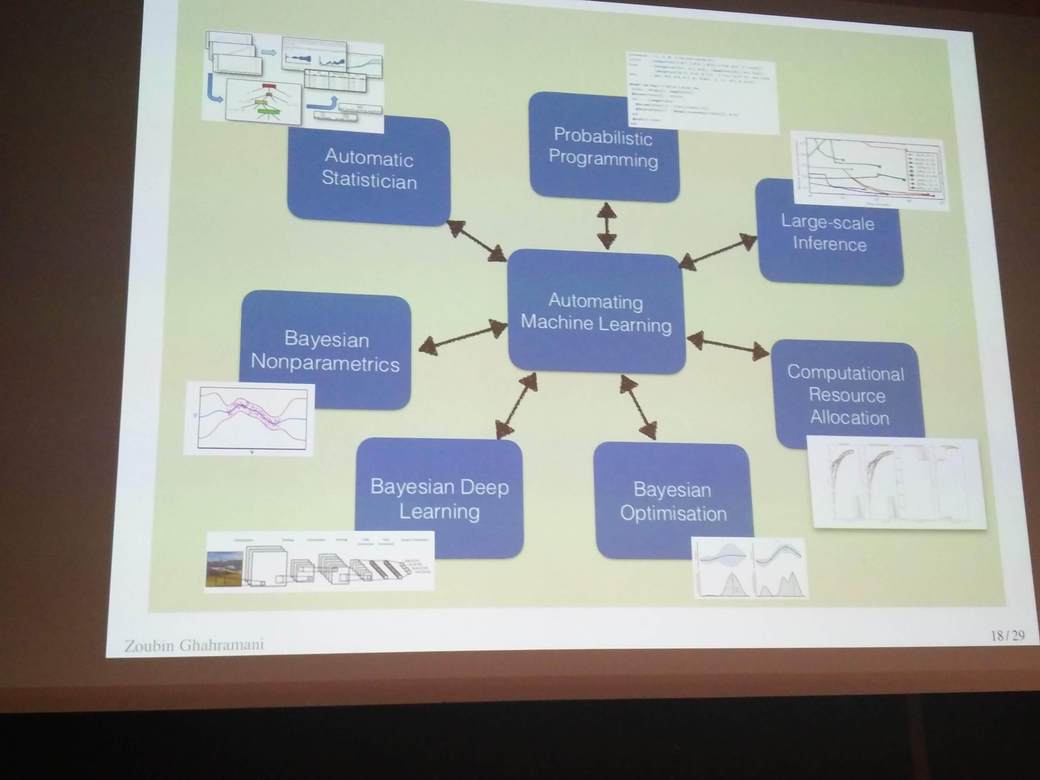
Zoubin Ghahramani (Uber AI and Cambridge) discussed the importance of moving towards understandable machine learning architectures, also in practice.




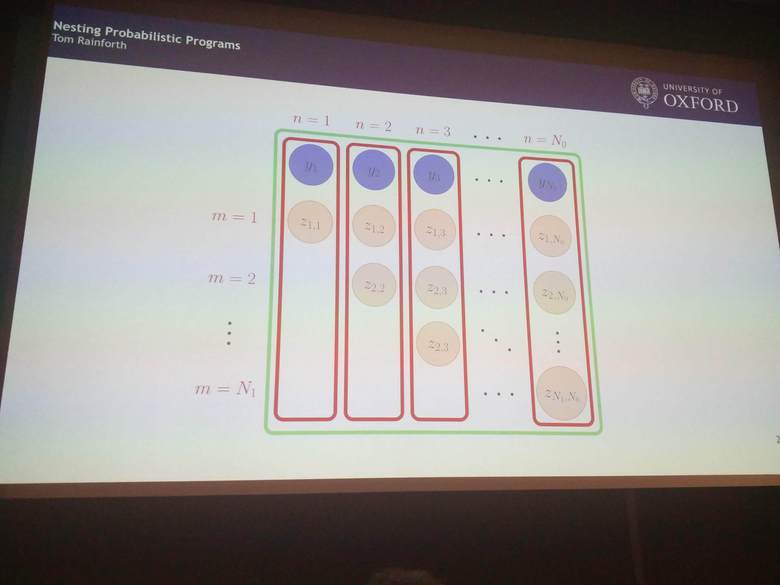
Tom Rainforth (Oxford) discusses how to allow nested inference, where the inferred result of one probabilistic program can be used efficiently in another one.



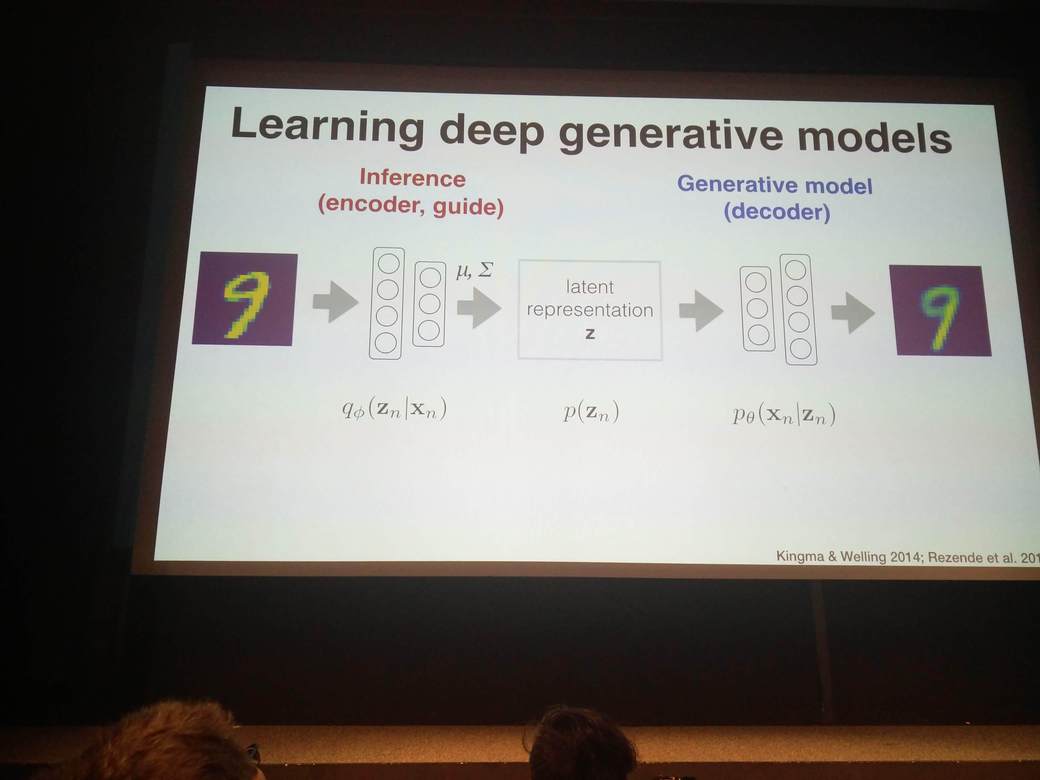
Brooks Paige (Alan Turing Institute) presents a discussion on how to use deep neural networks with probabilistic models, in a way that some of the parameters are still easily interpretable.

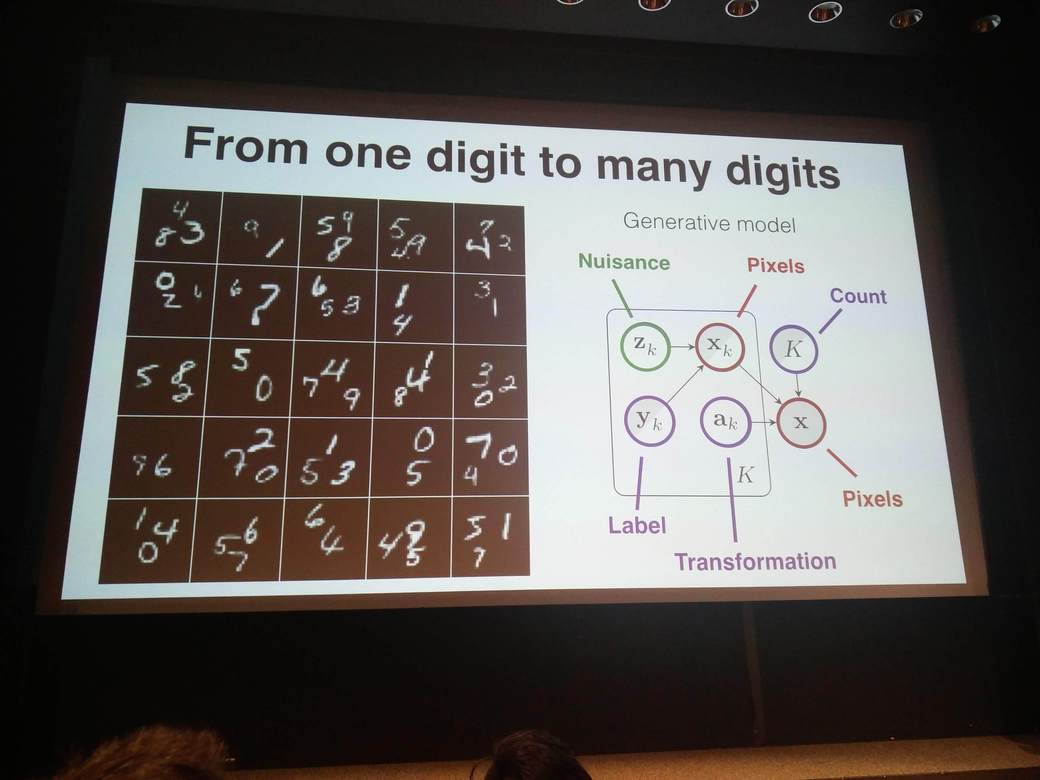

Daniel Ritchie (Brown) showed how probabilistic programming could be used in the field of computer graphics to generate new interesting computer models.

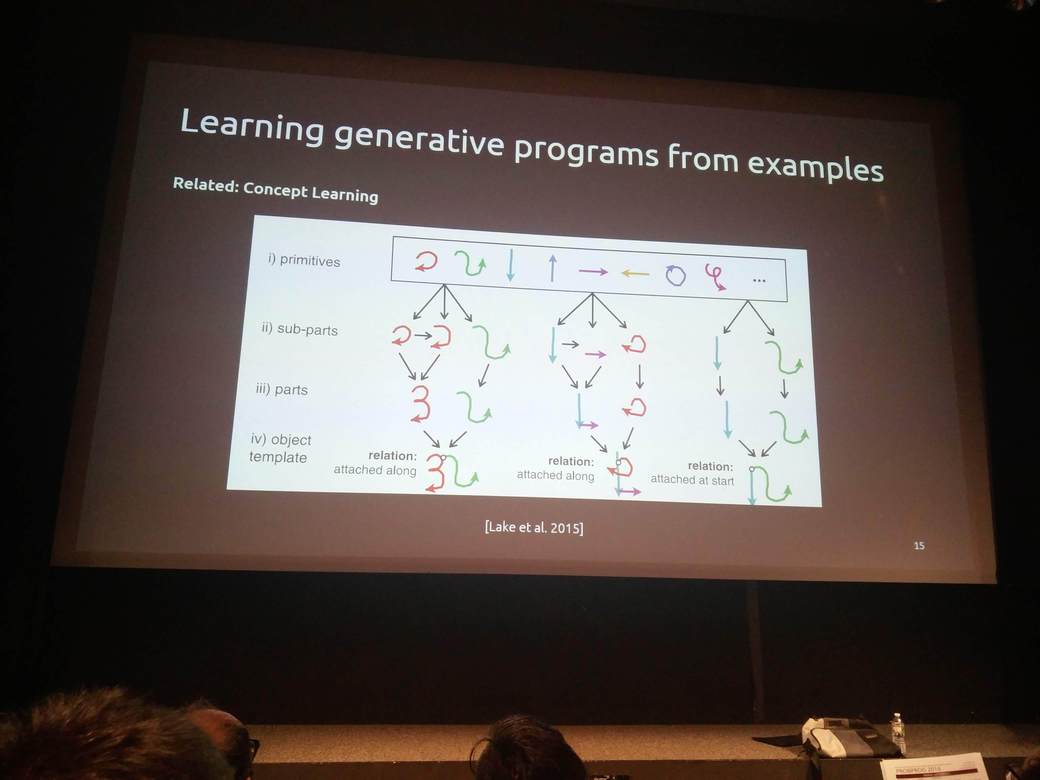
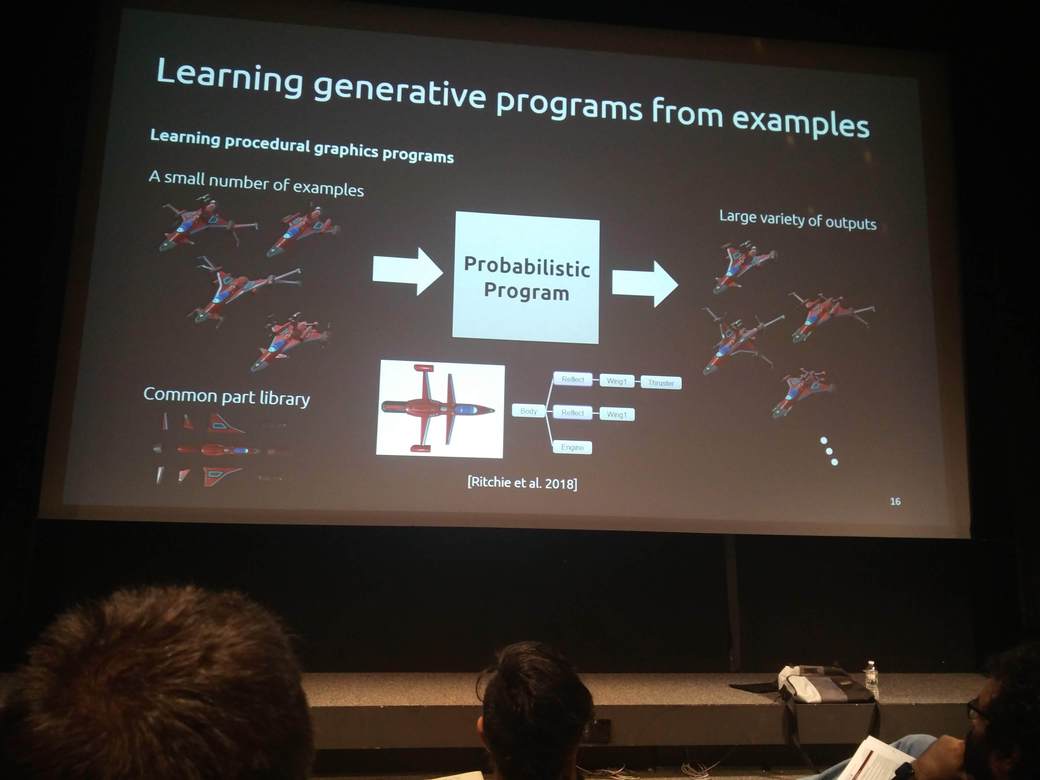
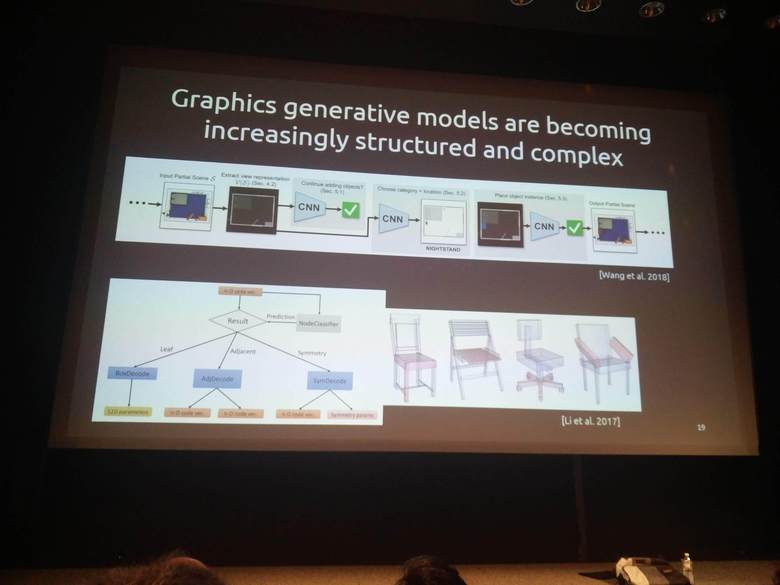
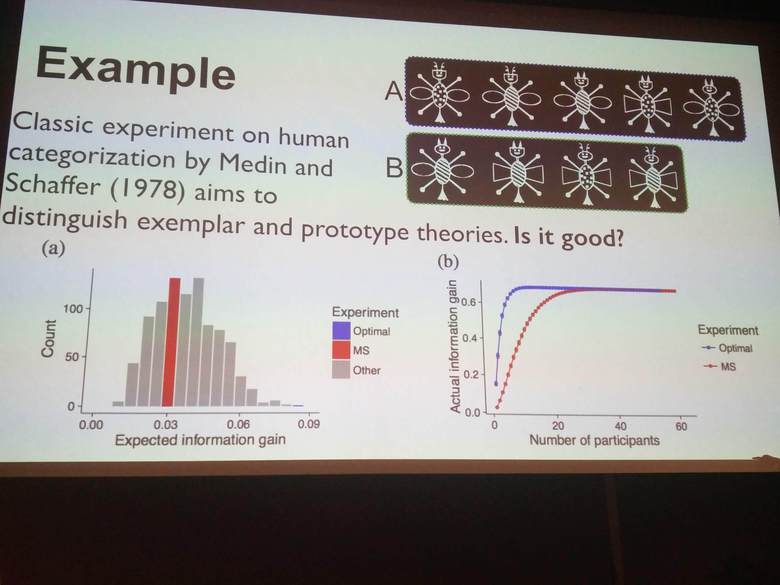
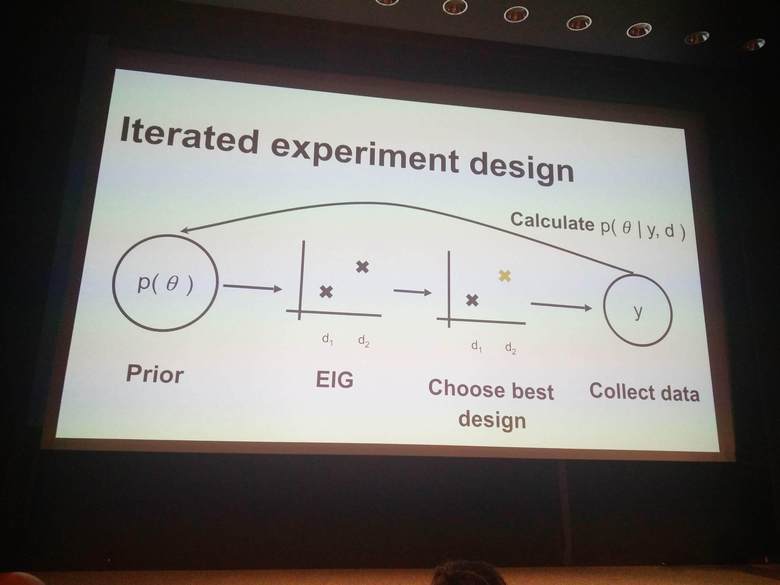
Noah Goodman (Uber AI and Stanford) presents how to use probabilistic programming for inferring optimal experiment designs for scientific experiments. You can try their contributed code in the development version of Pyro, in the pyro.contrib.oed contributed module.



Fun and food in Boston
Naturally, I also had the opportunity to visit a few interesting places in Boston, like Fenway park and the Museum of Science.





I can also recommend the famous lobster rolls and cannolis at Mike’s Pastry.

